论这年头复现深度学习的成果有多难🐶
TLDR: 不折腾就不会死系列
背景1
大约7,8年前国内刚能买到特斯拉的时候, 我曾关注了一段时间自动驾驶技术的进展, 希望能判断自动驾驶技术是否已经足够成熟了. 毕竟特斯拉的一大卖点就是号称能自动驾驶. 而作为一个码农, 我有时连自己写的代码都不相信, 又怎么会轻易把性命托付给别人写的代码呢🐶.
当时基于深度学习方法正持续在各项任务中刷榜, 所以似乎业界对于最终能实现自动驾驶的目标普遍乐观. 我一开始可能也挺乐观, 直到在朋友的自动驾驶中的特斯拉上差点经历了撞车.
之后似乎每年都可以读到几篇自动驾驶中的电动汽车发生恶性事故的报道. 业界好像也渐渐变得没那么自信, 自动驾驶落地的目标从L5, L4一路降到L2. 我也就没再继续关注了. 而当去年爆出特斯拉当年的自动驾驶宣传视频造假[1]的时候, 我好像也没觉得特别意外.
背景2
最近考虑给家里购置新车, 恰逢国内新能源汽车发展迅猛, 就去试驾了一些国产新能源品牌. 其中极氪007[2]的AR-HUD给我留下了深刻印象. 其以HUD的形式显示了在车身四周识别到的车辆和行人等, 不用像其他品牌那样低头去看仪表盘或中控. 这样就算识别到的结果不用于自动驾驶, 用来给驾驶员补盲也是极好的. 而且在没有激光雷达的车型上也有实装, 说明是种纯视觉方案. 这又让我来了兴趣, 再次关注起自动驾驶技术(尤其是感知方面)的进展.

初步调研的结果, 近几年一种名为Transformer的架构在深度学习领域大杀四方. 在自动驾驶领域则直接导致了底层感知框架的洗牌. 最新的趋势则是在BEV(Bird’s-Eye-View)表征中做感知. 找到了一篇据说是效果最好的开源方案BEVFormer[3]. 于是我就决定复现一下, 不想却是一系列折腾的开始.
硬件方案
第一步安装[4]的时候就卡住了. BEVFormer依赖了OpenMMLab[5]的mmcv和mmdet3d等, 需要依赖CUDA. 虽然之前关注深度学习和自动驾驶的时候在家里装过一台GeForce 1080的PC, 但在结婚以后就给老婆用了. 我自己则是一直在用Mac, 再也没用过PC. 这年头老黄的RTX 40系显卡那么贵, 重新装一台PC似乎要花比当年更多的钱. 思来想去, 目前我手头性能最好的PC似乎是–Steam Deck?
要给Steam Deck这样的“PC”装上显卡, 显然无法内置而只能外接[6]. 然而外接也有问题. 通常外接显卡都需要利用USB4[7]或是雷雳[8]这样的高速线缆, 这样才能匹配上PCIe 4.0[9]的传输速率. 而Steam Deck[10]的Type-C只有USB 3.2[11], 并且市面上似乎也没有USB3的外接显卡方案. 难道就没有办法了吗?
记得当年还给公司组过一台多卡的工作站, 但因为主板大小和显卡厚度的关系, 导致显卡挨得很近无法有效散热:

而且当年似乎还没有改造显卡风道的廉价方案, 所以最终采用了延长PCIe接口的方式空开显卡之间的距离:

其实这已经可以视为一种“外接”显卡的方案了. 但Steam Deck上并没有PCIe接口, 却存在一种曲线救国的方式, 那就是用来插SSD的M.2[12]. 不过虽然M.2号称可以支持到PCIe 4.0 x4, 具体支持到什么程度还是要看制造商的心情. 但至少从接口上看, 这条链路能跑通. 并且市面上已经有成熟的M.2转OCuLink[13]的eGPU方案.

顺带一提, 早些年Intel芯片的Mac曾经也可以外接显卡[14]. 但近年来Mac都用上了自家的M芯片, 而且老黄家的显卡驱动在Mac早就断更了多年, 所以用Mac外接显卡如今并不能成为一个选项.
硬件准备
给Steam Deck换上M.2转接口没什么问题, 只要是给Steam Deck升级过内置SSD的都可以熟门熟路:

但因为卸下了SSD, 所以Steam Deck就没有了内部存储器, 需要从外部存储器上启动. 最简单的方法是创建一个Windows To Go的启动U盘[15]. 插上外接显卡和启动盘, Steam Deck启动!
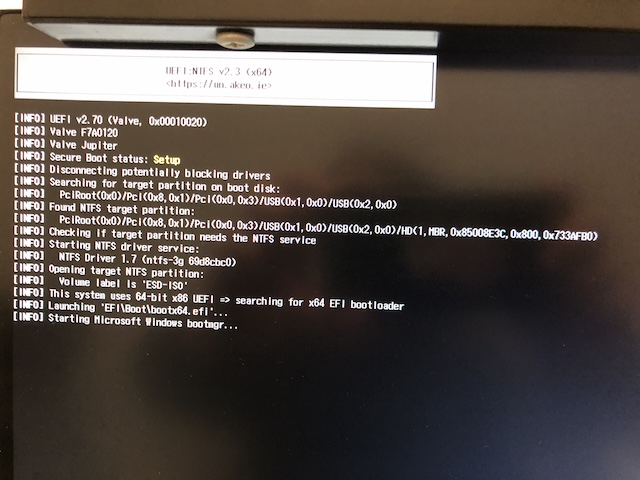
然后就卡住不动了!
换了Ubuntu的启动盘则是在GRUB菜单直接黑屏. 油管上能找到一些做相同尝试的人遇到同样的问题[16], 而最终成功的方案都是换了AMD的显卡🐶. 由于缺乏调试Steam Deck的手段, 这个方案陷入了僵局.
硬件方案2
左思右想之后想起还有一台多年前淘汰下来正在积灰的迷你PC: Dell OptiPlex 3070. 感受一下配置:
- Intel Pentium G5420T (双核四线程)
- 2 x 4 GB DDR4 (之后升级过内存)
- M.2 (最高支持1T SSD)
因为是迷你PC, 为了节约内部空间, 硬盘架是盖在M.2接口上的. 而换上转接口插上显卡之后, 硬盘架就放不下了. 好在上面已经准备了启动盘, 所以也没问题. 插上启动盘启动!

然后就成功了! Windows启动后甚至还自动装好了最新的NV显卡驱动.
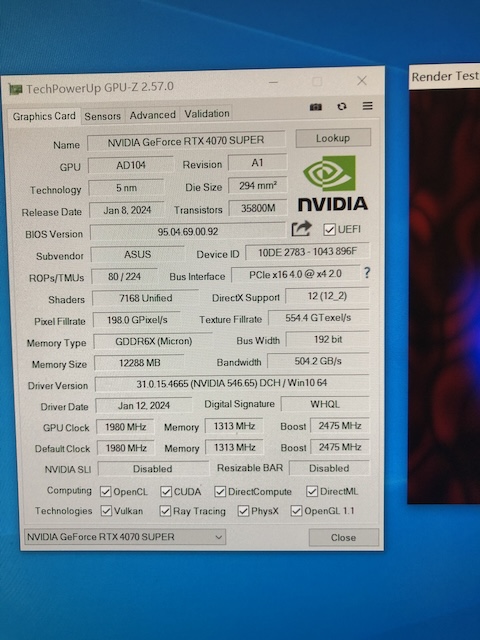
不过接口速度就只有PCIe 2.0 x4, 只能说聊胜于无吧.
软件开发环境
当年搞过深度学习的人大多都被Linux下的NV驱动的安装折磨过. 如今Windows下有WSL, 还需要折腾吗? 试下来最初的体验简直可以用丝滑来形容. 由于Windows已经自动装好了NV驱动, 只要再装个WSL, 下载个虚拟机, 虚拟机打开就能直接看到显卡:
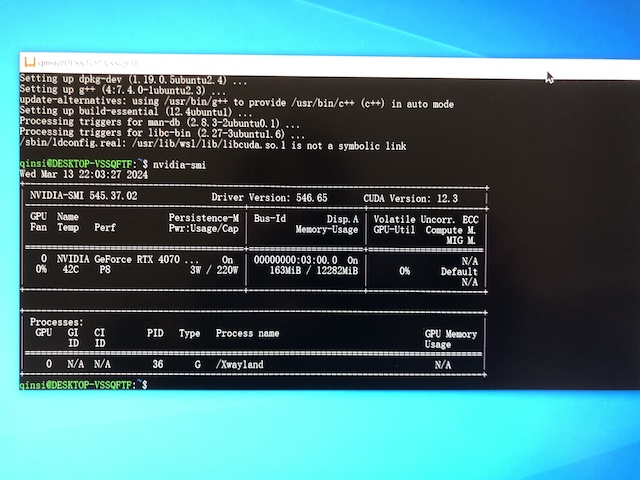
还有更好的. 安装了VS Code之后, 其会自动检测到WSL并安装相关插件. 之后只要在WSL虚拟机中的任何目录里输入code ., 就能打开主机中的VS Code, 并能在VS Code中直接编辑和运行虚拟机中的文件!
你大爷微软还是你大爷呀!
继续安装
回到BEVFormer的安装步骤[4]. 可以看到作者已经尽可能限制了复现所依赖的软件版本, 从Python到PyTorch到CUDA, 不一而足. 但在从源码安装mmdet3d时还是遇到了依赖版本冲突的情况. 由于没有使用某种能锁定依赖版本的机制, 导致安装时拉取了某些依赖的最新版本, 与作者希望固定下来的旧版本软件产生了冲突. 而众所周知pip没有能自动解决依赖冲突的能力, 只能靠手工一个个安装冲突依赖的旧版本来解决. 好在冲突也不多, 主要是numpy, sklearn这些常见且更新比较勤快的包, 多尝试安装几个不同的旧版本就可以了.
下面继续安装detectron2的时候也有上述同样的问题. 而且又出现了一个新问题, 说是没有nvcc. 所以Windows自动安装的NV驱动并不包含CUDA Toolkit[17], 仍旧需要手动安装. 并且需要与之前安装的软件依赖的CUDA版本一致. 这里需要的是CUDA 11.1. 顺便吐槽下NV官网上旧版本的CUDA链接不大好找, 还不如从搜索引擎直接进入.
至此软件依赖应该都已经安装好了. 下一步要准备数据.
数据准备
根据说明[18], 需要下载nuScenes[19]的完整数据. 不看不知道, 一看吓一跳. 需要从AWS上拉下来的压缩包总共约有300G. 如果估计解压后有500G的话, 就需要将近1T的剩余空间才能放得下. 不得已只能再外接一个移动硬盘.
更没想到的是, 下载已经很慢了, 解压还要更慢. 解压几百G的数据, 写入硬盘的速度到后面就只有几百K/s. 在Windows/WSL/Mac中解压都一样; 外接移动硬盘或是SSD也区别不大. 而如果直接复制压缩包的话速度可以有上百M/s. 观察下来发现写入速度慢的时候正在解压大量的小文件. 除了硬件的限制外也有可能是文件系统的锅, 不过时间有限没有尝试比较不同的文件系统. 这可如何是好?
于是想到既然解压慢, 有没有可能不解压直接用呢. 比如通过FUSE[20]直接把压缩包当成文件系统挂载. 搜了一下还真的找到了个叫ratarmount[21]的工具, 其使用场景里就有直接挂载ImageNet压缩包的例子.
数据挂载
于是就尝试用ratarmount去挂载压缩包, 可以看到其会为压缩包创建索引, 用来在需要时快速定位包内文件的位置. 不过跑到一半就被Killed了. 这个我熟, OOM了呗. 就准备把系统虚拟内存调大点试试. 然后研究了半天Windows的虚拟内存在哪里设置, 经过一连串的点击和设置以及重启…还是被Killed.
这时才反应过来该调的应该是WSL虚拟机中的内存[22], 居然是需要在用户目录创建一个.wslconfig文件进行配置. 分配好足够的内存之后数据挂载就成功了.
数据创建
根据说明[18], 接下来需要跑一个脚本来创建一些pickle文件. 不过一跑就出错, 说是ImportError. 看了下除了tools/data_converter/indoor_converter.py之外, 这个目录中的其他文件用的都是相对import. 所以要么修改PYTHONPATH要么把这个文件的import也改成相对的.
此外, 作者默认把生成的pickle文件写到原始的数据目录里. 但我在挂载压缩包时创建的文件系统是只读的, 写入数据就会失败. 好在这个创建数据的脚本可以指定输出目录, 我就指定了本地的另一个目录, 完成了数据的创建.
测试
下载了一个tiny[23]模型的权重来测试[24]. 作者默认用8个GPU, 然而我把参数改成1以后跑起来却是问题一个接一个.
首先是报错:
RuntimeError: NCCL error in: ../torch/lib/c10d/ProcessGroupNCCL.cpp: 911,
unhandled system error
还真是非常有用的信息🐶. NCCL是多卡训练时用到的库[25], 所以就算我在参数里指定了只用1个GPU, 脚本里最终还是用到了NCCL? 此时需要设置环境变量NCCL_DEBUG[26], 调成WARN或INFO看下更详细的信息:
NCCL WARN Could not find real path of /sys/class/pci_bus/...
这就很有意思了, NCCL说找不到显卡? 搜了一下还真是, 旧版本的NCCL在WSL中不支持多GPU[27]. 由于作者限制了PyTorch的版本, 也就限制了NCCL的版本. 要单独升级NCCL版本的话还要重新编译PyTorch. 先想想别的办法吧.
看了下tools/test.py中有这样的代码[28]:
if args.launcher == 'none':
distributed = False
else:
distributed = True
所以只要去掉launcher参数就好了嘛? 才怪. 跑到下面又报错了[29]:
if not distributed:
assert False
这得是有多不待见单卡用户啊. 这下改完以后总能跑了吧? 拿衣服, 直接Core Dump:
Illegal instruction
什么都不说了, 鼓掌吧👏.
鼓完掌祭出gdb, 在断点处反汇编, 看到了这样的画面:
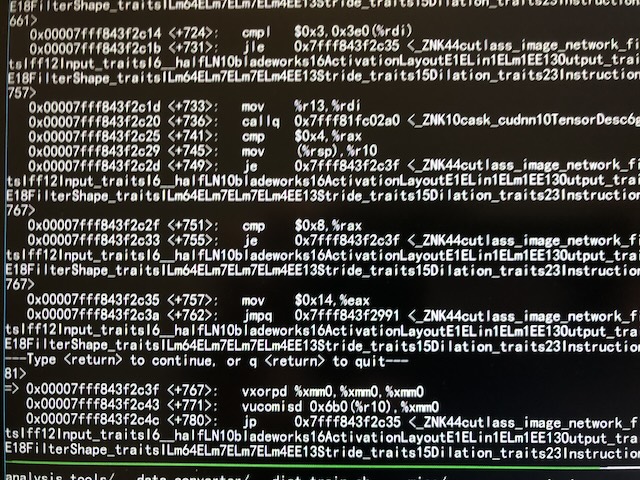
箭头所指处的vxorpd是一条AVX指令[30]. 所以问题就在于这台OptiPlex 3070的Pentium G5420T只支持SSE, 不支持AVX指令[31].
此外虽然断点所处的文件是libtorch_cuda.so, 但在PyTorch代码库的历史版本和最新版本中似乎并没有所谓的cutlass_image_network的代码. 而cutlass[32]则是NV的一个基于CUDA的加速库. 所以在不支持的CPU上调用不存在的指令这事是谁的锅呢? 懂行的可以说说.
测试2
幸好这台OptiPlex除了赛扬和奔腾以外, i3/i5/i7都可以插[33]. 这些都是支持AVX指令集的, 就是年代久远只能买到华强北的二手散片, 价格倒是不贵. 换了CPU以后剩下的就都是小问题了.
跑到Evaluation的时候又报错, 说找不到数据集. 看了下代码[34], 模型的数据目录都被写死了, 似乎也没有提供覆盖的方法. 按照作者提供的说明里组织目录结构[18]的话就不会有问题, 但因为我在上面创建数据时为了回避只读文件系统的问题, 使用了别的路径, 到这里就不行了. 解决的方法也很简单, 把创建出来的数据文件也打个包跟其他数据包挂载到一起就好了.
这样终于跑出了结果:
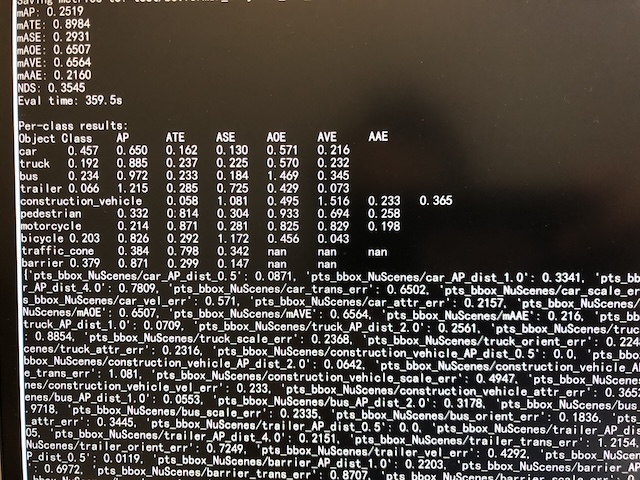
可以看到mAP: 0.2519, NDS: 0.3545, 与作者报告的结果一致[23].
可视化结果:
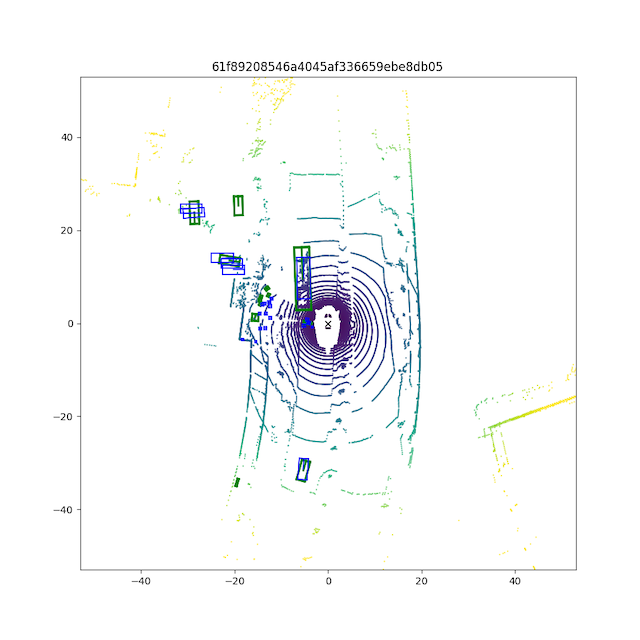

小结
简要总结下这次遇到的问题和解决方法:
- 需要CUDA但没有PC –> Steam Deck加eGPU
- Steam Deck没有USB4 –> M.2转接OCuLink
- 卸了SSD没有了系统盘 –> 外接U盘启动Windows To Go
- Steam Deck无法启动 –> 换Dell OptiPlex
- Python依赖冲突 –> 手动降级某些依赖包的版本
- 缺少
nvcc–> 安装对应版本的CUDA Toolkit - 数据解压太慢 –> 用
ratarmount直接挂载- 挂载时内存不足 –> 调整WSL虚拟机中的内存大小
- 创建数据脚本错误 –> 修正import
- 只读挂载的文件系统无法写入 –> 指定另外的写入路径
- 测试脚本报NCCL错误 –> 修改脚本只使用单卡
- 测试脚本报非法指令 –> 换CPU
- 模型的数据目录被写死 –> 把创建出来的数据也挂载到原始数据的目录中
由此可见这年头复现别人的成果有多难🐶
当然上述大部分问题都是折腾出来的. 理想情况就是拥有和作者一样的软硬件环境. 只要作者注意下锁死依赖的版本, 并且代码里不要写死太多东西就可以. 但多卡环境依旧是超出消费级的范畴的. 要不是我留着老黄的显卡还有别的用途(才不是为了打游戏!), 我会选择云端的环境. 就是这次这数据量, 使用云盘的开销可能也比较大.
此外也可以看到, 上述过程也就是一个发现问题->作出决策->解决问题的迭代过程. 最近有个叫Devin[35]的AI就号称能像人类一样完成这样的工作. 要是云端的沙盒环境足够强大的话, 它是否能把人类从重现别人工作的任务中解放出来呢? 感觉可以期待一下.
这次还有另一个收获, 那便是对Windows下开发环境的印象大为改观. 虽然WSL还有些这样那样的问题, 但应付日常开发显然已经问题不大了. 看得出来微软是在持续不断地优化开发体验的. 相比之下苹果这几年的行为就像在赶走开发者一样, 硬件上跟x86分道扬镳不说, 软件上也时不时会看到有开发者常用的工具出错[36]. 如果Mac无法确保一个稳定的开发环境的话, 还不如用PC吧.
参考
- [1] Tesla engineer testifies that 2016 video promoting self-driving was faked
- [2] Zeekr 007
- [3] BEVFormer: a Cutting-edge Baseline for Camera-based Detection
- [4] Step-by-step installation instructions
- [5] OpenMMLab
- [6] eGPU.io
- [7] USB4
- [8] Thunderbolt (interface)
- [9] PCI Express
- [10] Steam Deck LCD
- [11] USB 3.2
- [12] M.2
- [13] OCuLink: What It Is, Why You Need It, and Where To Get It
- [14] Use an external graphics processor with your Mac
- [15] How to install Windows on a Steam Deck
- [16] We Put A GPU on the Steam Deck
- [17] CUDA Toolkit
- [18] prepare_dataset
- [19] nuScenes by Motional
- [20] Filesystem in Userspace
- [21] Random Access Tar Mount (Ratarmount)
- [22] Advanced settings configuration in WSL
- [23] Model Zoo
- [24] getting_started
- [25] NCCL
- [26] Environment Variables
- [27] NCCL tests don’t work on WSL
- [28] BEVFormer/tools/test.py
- [29] BEVFormer/tools/test.py
- [30] AVX Instructions
- [31] Intel® Pentium® Gold G5420T Processor
- [32] CUDA Templates for Linear Algebra Subroutines
- [33] Dell OptiPlex 3070 Tower Setup and Specifications
- [34] BEVFormer/projects/configs/bevformer/bevformer_tiny.py
- [35] Introducing Devin
- [36] Java users on macOS 14 running on Apple silicon systems should consider delaying the macOS 14.4 update