用 TypeScript 实现 Visitor 模式
在编译器的实现中经常会看到Visitor模式,不过为什么要使用Visitor模式通常讲得不是很清楚。我看到过的最清晰的解释之一还是Bob的书里的[1]。不过因为是Java实现的,对于其他语言可能不完全适用。这里简单探讨下用TypeScript实现的情况。
假设现在有两种AST节点,数字NumberLiteral和二元表达式BinaryExpr:
abstract class AstTree {}
class NumberLiteral extends AstTree {
constructor(public readonly num: number) {
super()
}
}
class BinaryExpr extends AstTree {
constructor(
public readonly lhs: NumberLiteral,
public readonly op: string,
public readonly rhs: NumberLiteral
) {
super()
}
当对表达式求值时,就需要遍历AST节点:
function evaluate(t: AstTree): number {
if (t instanceof NumberLiteral) {
return t.num
}
if (t instanceof BinaryExpr) {
return eval(`${evaluate(t.lhs)} ${t.op} ${evaluate(t.rhs)}`)
}
throw new Error('unknown ast')
}
const expr = new BinaryExpr(new NumberLiteral(1), '+', new NumberLiteral(2))
console.log(evaluate(expr))
画成表格的形式:
| 类型\方法 | evaluate() |
|---|---|
| NumberLiteral | ✅ |
| BinaryExpr | ✅ |
未来对于这张表格的扩展有两种方式,一种是增加新的行,也就是增加新的AST节点:
| 类型\方法 | evaluate() |
|---|---|
| NumberLiteral | ✅ |
| BinaryExpr | ✅ |
| StringLiteral | ❌ |
| … | ❌ |
显然这时对于已存在的列,都需要增加对新行的处理。另一种是增加新的列,也就是增加新的遍历方法:
| 类型\方法 | evaluate() | lookup() | … |
|---|---|---|---|
| NumberLiteral | ✅ | ❌ | ❌ |
| BinaryExpr | ✅ | ❌ | ❌ |
显然这时对于已存在的行,都需要增加对新列的处理。当然还有可能是需要同时增加新的行和新的列:
| 类型\方法 | evaluate() | lookup() | … |
|---|---|---|---|
| NumberLiteral | ✅ | ❌ | ❌ |
| BinaryExpr | ✅ | ❌ | ❌ |
| StringLiteral | ❌ | ❌ | ❌ |
| … | ❌ | ❌ | ❌ |
各种不同的写法,包括 Visitor 模式想要解决的问题,都是希望以最小的改动已有代码的代价,完成对这张表格的扩展。
假设已有N种不同类型的AST节点和M种不同的遍历方法(N行M列的表格),下面来具体看下不同的写法的代价。
1. 独立的遍历方法
这就是上文中使用的方法,在一个独立的方法中完成对所有不同类型节点的遍历。由于需要显式判断节点的类型,就不那么面向对象,在用面向对象语言的实现中很少见。
当需要新增节点类型(新增行)时,在所有已有的遍历方法中都需要增加对节点类型的处理,所以代价就是修改M个遍历方法。
2. Interpreter 模式
由于上面第一种写法不够面向对象,所以在面向对象语言里通常会使用 Interpreter 模式:
abstract class AstTree {}
class NumberLiteral extends AstTree {
constructor(public readonly num: number) {
super()
}
+
+ eval() {
+ return this.num
+ }
}
class BinaryExpr extends AstTree {
constructor(
public readonly lhs: NumberLiteral,
public readonly op: string,
public readonly rhs: NumberLiteral
) {
super()
}
+
+ eval() {
+ return eval(`${this.lhs.eval()} ${this.op} ${this.rhs.eval()}`)
+ }
}
调用时:
console.log(expr.eval())
跟第一种写法相比的话,相当于把独立的遍历方法中对不同类型节点的处理拆到了节点各自的实现中。
然而当需要新增一种遍历方法(新增列)时,则需要对已有的节点类型都增加新方法的实现,所以代价就是修改N种节点类型。
3. Visitor 模式
Visitor 模式又多加了一层调用,所以理解起来可能不是很直观:
abstract class AstTree {}
class NumberLiteral extends AstTree {
constructor(public readonly num: number) {
super()
}
accept(v: AstVisitor<unknown>) {
return v.visitNumberLiteral(this)
}
}
class BinaryExpr extends AstTree {
constructor(
public readonly lhs: NumberLiteral,
public readonly op: string,
public readonly rhs: NumberLiteral
) {
super()
}
accept(v: AstVisitor<unknown>) {
return v.visitBinaryExpr(this)
}
}
interface AstVisitor<T> {
visitNumberLiteral(n: NumberLiteral): T
visitBinaryExpr(e: BinaryExpr): T
}
class EvalVisitor implements AstVisitor<number> {
visitNumberLiteral(n: NumberLiteral) {
return n.num
}
visitBinaryExpr(e: BinaryExpr) {
return eval(`${this.visitNumberLiteral(e.lhs)} ${e.op} ${this.visitNumberLiteral(e.rhs)}`)
}
}
调用时:
console.log(expr.accept(new EvalVisitor()))
另一本书[2]上有张比较清晰的图,这里就借用一下:
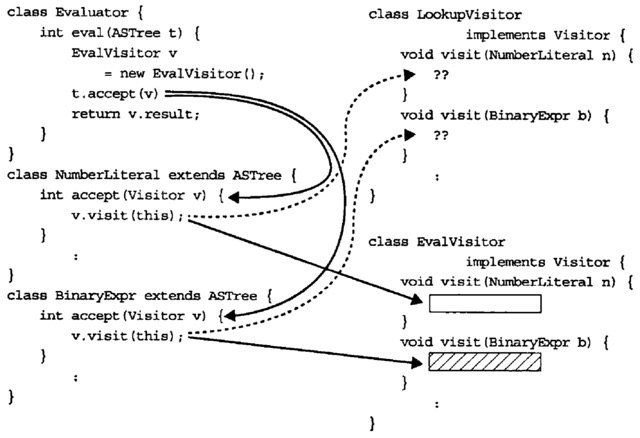
注意图中的代码是Java的,利用了Java中方法的重载。ts里没有编译器支持的方法重载,所以需要通过方法名区分。但结果是一样的,都是一个方法对应一种节点类型。从代码组织上来看,其实和第一种方法一样,又把对不同节点类型的处理逻辑放在了一起。
这样在新增节点类型(新增行)时,首先需要修改Visitor接口,增加新的visit方法;然后需要让已有的Visitor类都实现新增的方法。所以代价就是修改M个Visitor的实现类和1个Visitor接口。
4. 去掉 Visitor 接口
光从代价上来看,方法3甚至还不如方法1,所以很自然的想法是去掉 Visitor 接口:
class NumberLiteral extends AstTree {
constructor(public readonly num: number) {
super()
}
- accept(v: AstVisitor<unknown>) {
+ accept(v: any) {
return v.visitNumberLiteral(this)
}
}
class BinaryExpr extends AstTree {
constructor(
public readonly lhs: NumberLiteral,
public readonly op: string,
public readonly rhs: NumberLiteral
) {
super()
}
- accept(v: AstVisitor<unknown>) {
+ accept(v: any) {
return v.visitBinaryExpr(this)
}
}
-interface AstVisitor<T> {
- visitNumberLiteral(n: NumberLiteral): T
- visitBinaryExpr(e: BinaryExpr): T
-}
-class EvalVisitor implements AstVisitor {
+class EvalVisitor {
visitNumberLiteral(n: NumberLiteral) {
return n.num
}
visitBinaryExpr(e: BinaryExpr) {
return eval(`${this.visitNumberLiteral(e.lhs)} ${e.op} ${this.visitNumberLiteral(e.rhs)}`)
}
}
代价则是没有了编译时的检查。不过这也算是动态语言的基操了。
修改的代价就跟第1种方法一样了,在新增节点类型(新增行)时,只需要修改M个Visitor的实现类。
5. accept() 移到基类
受到上一种方法的启发,我们可以进一步利用动态语言的特性:
abstract class AstTree {
+ accept(v: any) {
+ return v[`visit${this.constructor.name}`](this)
+ }
}
class NumberLiteral extends AstTree {
constructor(public readonly num: number) {
super()
}
-
- accept(v: any) {
- return v.visitNumberLiteral(this)
- }
}
class BinaryExpr extends AstTree {
constructor(
public readonly lhs: NumberLiteral,
public readonly op: string,
public readonly rhs: NumberLiteral
) {
super()
}
-
- accept(v: any) {
- return v.visitBinaryExpr(this)
- }
}
不过这样也只是少写些代码,对修改的代价没有影响。
结论
总结一下上面的几种方法,其中N为已有节点类型数量,M为已有遍历方法数量:
| 方法\代价 | 新增节点类型 | 新增遍历方法 | 备注 |
|---|---|---|---|
| 独立的遍历方法 | M | 不够OO | |
| Interpreter 模式 | N | N » M 时不会用 | |
| Visitor 模式 | M + 1 | 多改一个接口;编译时检查 | |
| Visitor 模式(无接口) | M | 无编译时检查 | |
| Visitor 模式(基类accept) | M | 只需要一个accept;无编译时检查 |
在实际项目中,通常AST节点类型的数量N会远大于遍历方法的数量M,所以通常不会使用Interpreter模式。而光看修改代价的话,Visitor模式和写独立方法差不多,区别只是写法上够不够OO而已。但在节点类型很多时,可能还是会希望借助编译器来帮忙检查是否所有的节点类型都得到了处理。你在实现这样的需求时,会用哪种方法呢?